linux
Free Linux Training Notes
Free stuff!
When we started our IT consulting company, Applepie Solutions back in 2004 we looked at working in a number of different areas including Java development, C# development, software engineering consulting and Linux support. At the time, we thought there might be an opening for Linux training also, and we figured it was one way of marketing our services to prospective Linux customers. So we added Linux training to our reportoire of services and I set out to put together some training material. We started with an Introduction to Linux course after finding some interested customers around the Galway area. After looking at our options for training material, including possibly licensing some of the main Linux distributors training material, I decided to go ahead and create our own, little realising what a mammoth task preparing good training materials is. My goals in putting together the course (and subsequent ones) were,
- Provide training material that addressed the three main distributions – Red Hat, SuSE and Debian. So I set out to describe the general concept of whatever area we were looking at in the training material and then discuss the specifics of that concept on each of the main distributions.
- Cover what people need to know but give some context. There are things anyone using a Linux system should know. Then our customers pointed out some things they wanted to cover. Finally, I took a look at the content of exams from various organisations such as LPI and tried to address the key points from their perspective also (without, I should mention, covering things such as how to set up a modem on your Linux system – I know there are people out there that still need this, but they’re in a minority in our world anyway).
- Give enough material in the notes that people had a useful reference afterwards also. Okay, in the early days I found this part quite useful for myself also – I mean, no matter what your Linux knowledge is, giving a 5 day training course without any prompts can be intensive – if you can have some guiding notes for your own reference it helps!
I think we mainly succeeded in these goals – most customers we delivered training to gave us excellent feedback – on both our delivery and the quality of our training material.
After some initial success with our Introduction to Linux (and because preparing one training course wasn’t enough of a struggle), I also prepared 2 subsequent courses, one on Linux System Administration and Support intended to help those comfortable with Linux move to the next level of system administration or providing support to Linux users, and a short one on Linux Performance Tuning which scratches the surface of performance tuning and optimisation (it was intended as a half day or day long course for people comfortable with Linux).
We’re currently looking at restructuring our business and while we’re not exactly sure what the future holds yet, we’re pretty sure it won’t include us delivering Linux training. We could have just let the training materials languish at the bottom of our subversion repository, but really, this stuff doesn’t age well and we’ve always committed to giving something back to the Linux/open source/free software (delete as applicable) community where we could. I think this is one small opportunity for us to contribute back and with that in mind, we decided to release our training materials under a Creative Commons license – specifically, the Attribution Noncommercial Share Alike 3.0 Unported license. See the link for details of what you can and can’t do. In a nutshell, you’re free to share and remix the content of the training material as long as you properly attribute it. You’re not allowed to use this material for commercial purposes without our permission – but drop me a line if you do want to use these for some commercial purpose, we should be able to come to some agreement.
So what’s the catch? Apart from the license above? Nothing much really.
- Some of the materials haven’t been updated in about 2 years so they are showing their age in places. The performance tuning material has probably been most affected by this – but there are still plenty of useful concepts in there.
- The material is not without its bugs. Given the timeframes we worked under to prepare this material, there was never enough time to fully proof-read or correct every error, and there are sections that I’d love to rewrite from scratch if I was doing it again. But hey, they’re free!
- The material was all prepared using OpenOffice – for now we’re only making the material available in PDF format, but if someone is interested in other formats, again, let me know what you want them for and we’ll see what we can do.
- The table of contents don’t include page numbers. Sorry. If someone can tell me how to generate a table of contents for OpenOffice impress that includes slide/page numbers, I’ll be happy to rectify this.
So, without further ado, where are the notes? They are available for download from http://www.atlanticlinux.ie/opensource.php. In the words of the hugely successful Sirius Cybernetics Corporation Complaints division – Share and Enjoy.
Please, if you do find them useful – we’d like to hear about it, please let us know. Similarly, if you find any of the aforementioned bugs, let us know and I’ll see about fixing them, time permitting.
What a difference a Gig makes
We’re working on a project at the moment that involves deploying various Linux services for visualising Oceanographic modelling data using tools such as Unidata’s THREDDS Data Server (TDS) and NOAA/PMELS’s Live Access Server (LAS). TDS is a web server for making scientific datasets available via various protocols including plain old HTTP, OPeNDAP which allows a subset of the original datasets to be accessed and WCS. LAS is a web server which, using sources such as an OPeNDAP service from TDS, allows you to visualise scientific datasets, rendering the data overlaid onto world maps and allowing you to select particular variables from the data which you are interested in. In our case, the datasets are generated by the Regional Ocean Modeling System (ROMS) and include variables such as sea temperature and salinity at various depths.
The data generated by the ROMS models we are looking at uses a curvilinear coordinate system – to the best of my understanding (and I’m a Linux guy, not an Oceanographer, so my apologies if this is a poor explanation) since the data is modelling behaviour on a spherical surface (the Earth) it makes more sense to use the curvilinear coordinate system. Unfortunately, some of the visualisation tools, in particular LAS prefers to work with data using a regular or rectilinear grid. Part of our workflow involves remapping the data from curvilinear to rectilinear using a tool called Ferret (also from NOAA). Ferret does a whole lot more than regridding (and is, in fact, used under the hood by LAS to generate a lot of the graphical output of LAS) but in our case, we’re interested mainly in its ability to regrid the data from one gridding system to another. Ferret is an interesting tool/language – an example of the kind of script required for regridding is this one from the Ferret examples and tutorials page. Did I mention we’re not Oceanographers? Thankfully, someone else prepared the regridding script, our job was to get it up and running as part of our work flow.
We’re nearly back to the origins of the title of this piece now, bear with me!
We’re using a VMware virtual server as a test system. Our initial deployment was a single processor system with 1 GB of memory. It seemed to run reasonably well with TDS and LAS – it was responsive and completed requests in a reasonable amount of time (purely subjective but probably under 10 seconds if Jakob Nielsen’s paper is anything to go by). We then looked at regridding some of the customer’s own data using Ferret and were disappointed to find that an individual file took about 1 hour to regrid – we had about 20 files for testing purposes and in practice would need to regrid 50-100 files per day. I took a quick look at the performance of our system using the htop tool (like the traditional top tool found on all *ix systems but with various enhancements and very clear colour output). There are more detailed performance analysis tools (include Dag Wieers excellent dstat) but sometimes I find a good high-level summary more useful than a sea of numbers and performance statistics. Here’s a shot of the htop output during a Ferret regrid,

What is interesting in this shot is that
- All of the memory is used (and in fact, a lot of swap is also in use).
- While running the Ferret regridding, a lot of the processor is being spent in kernel activity (red) instead of normal (green) activity.
High kernel (or system) usage of the processor is often indicative of a system that is tied up doing lots of I/O. If your system is supposed to be doing I/O (a fileserver or network server of some sort) then this is good. If your system is supposed to be performing an intensive numerical computation, such as here, we’d hope to see most of the processor being used for that compute intensive task, and a resulting high percentage of normal (green) processor usage. Given the above it seemed likely that the Ferret regridding process needed more memory in order to efficiently regrid the given files and that it was spending lots of time thrashing (moving data between swap and main memory due to a shortage of main memory).
Since we’re working on a VMware server, we can easily tweak the settings of the virtual server and add some more processor and memory. We did just that after shutting down the Linux server. We restarted the server and Linux immediately recognised the additional memory and processor and started using that. We retried our Ferret regridding script and noticed something interesting. But first, here’s another shot of the htop output during a Ferret regrid with an additional gig of memory,
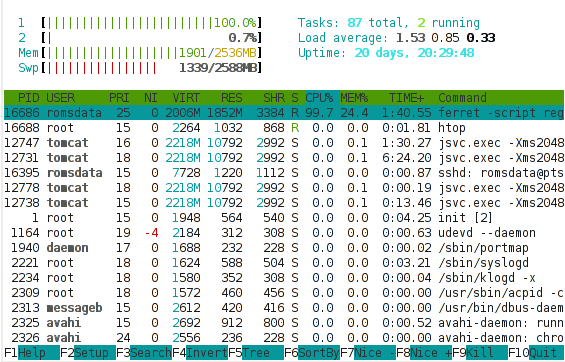
What is immediately obvious here is that the vast majority of the processor is busy with user activity – rather than kernel activity. This suggests that the processor is now being used for the Ferret regridding, rather than for I/O. This is only a snapshot and we do observe bursts of kernel processor activity still, but these mainly coincide with points in time when Ferret is writing output or reading input, which makes sense. We’re still using a lot of swap, which suggests there’s scope for further tweaking, but overall, this picture suggests we should be seeing an improvement in the Ferret script runtime.
Did we? That would be an affirmative. We saw the time to regrid one file drop from about 60 minutes to about 2 minutes. Yes, that’s not a typo, 2 minutes. By adding 1 GB of memory to our server, we reduced the overall runtime of the operation by 97%. That is a phenomenal achievement for such a small, cheap change to the system configuration (1GB of typical system memory costs about €50 these days).
What’s the moral of the story?
- Understand your application before you attempt tuning it.
- Never, ever tune your system or your application before you understand where the bottlenecks are.
- Hardware is cheap, consider throwing more hardware at a problem before attempting expensive performance tuning exercises.
(With apologies to María Méndez Grever and Stanley Adams for the title!)
Stress testing a PC revisited
I’m still using mostly the same tools for stress testing PCs as when I last wrote about this topic. memtest86+ in particular continues to be very useful. In practice, the instrumentation in most PCs still isn’t good enough to identify which DIMM is failing most of the time (mcelog sometimes makes a suggestion about which DIMM has failed and EDAC can also be helpful, but in my experience there is lots of hardware out there which doesn’t support these tools well). The easiest approach I’ve found to date is to take out one DIMM at a time and re-run memtest86+ … when the errors go away you’ve found your problematic DIMM – put it back in again and re-run to make sure you’ve identified the problem. If you keep getting the errors regardless of which DIMMs are installed, you may be looking at a problem with the memory controller (either on the processor or the motherboard depending on which type of processor you are using) – if you have identical hardware, you should look at swapping the components into that for further testing.
Breakin is a tool recently announced on the beowulf mailing list which looks like it has a lot of potential also and I plan on adding it to my stress testing toolkit the next time I encounter a problem which looks like a possible hardware problem. What looks nice about Breakin is that it tests all of the usual suspects including processor, memory, hard drives and it includes support for temperature sensors, MCE logging and EDAC. This is attractive from the perspective of being able to fire it up, walk away and come back to check on progress 24 hours later.
Finally, we’ve found the Intel MPI Benchmarks (IMB, previously known as the Pallas MPI benchmark) to be pretty good at stress testing systems. Anyone conducting any kind of qualification or UAT on PC hardware, particularly hardware intended to be used in HPC applications should definitely be including
an IMB run as part of their tests.
Categories
Archives
- September 2010
- February 2010
- November 2009
- September 2009
- August 2009
- June 2009
- May 2009
- April 2009
- March 2009
- February 2009
- January 2009
- October 2008
- September 2008
- August 2008
- July 2008
- June 2008
- May 2008
- April 2008
- March 2008
- February 2008
- November 2007
- September 2007
- April 2007
- March 2007
- February 2007
- January 2007
- December 2006
- September 2006
- July 2006
- June 2006
- April 2006